EPOCH: Jointly Estimating the 3D Pose of Cameras and Humans





T-CAP Workshop at ECCV, 2024
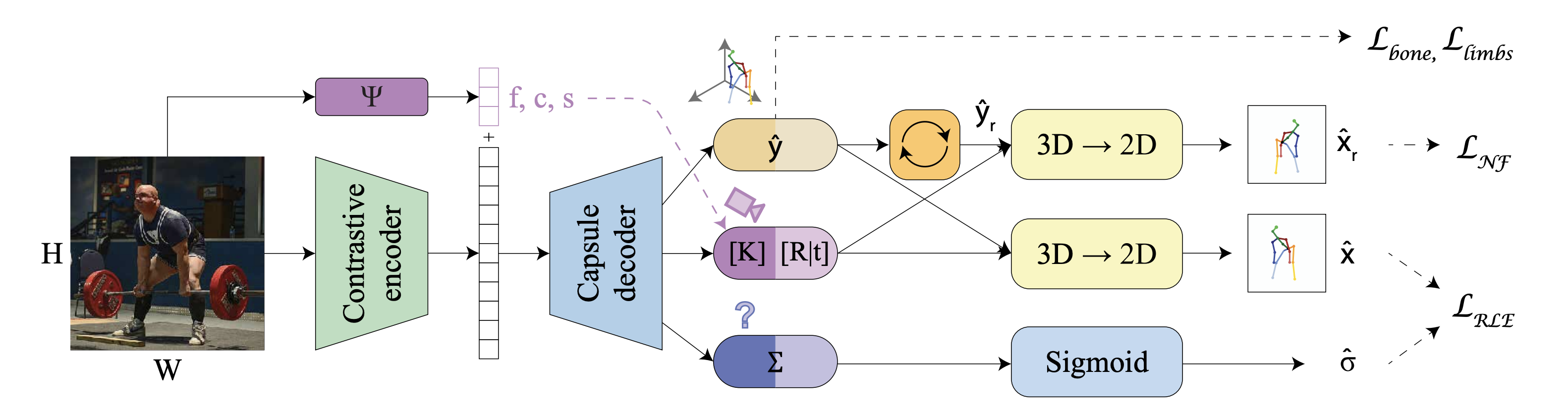
Abstract
Monocular Human Pose Estimation (HPE) aims at determining the 3D positions of human joints from a single 2D image captured by a camera. However, a single 2D point in the image may correspond to multiple points in 3D space. Typically, the uniqueness of the 2D-3D relationship is approximated using an orthographic or weak-perspective camera model. In this study, instead of relying on approximations, we advocate for utilizing the full perspective camera model. This involves estimating camera parameters and establishing a precise, unambiguous 2D-3D relationship. To do so, we introduce the EPOCH framework, comprising two main components: the pose lifter network (LiftNet) and the pose regressor network (RegNet). LiftNet utilizes the full perspective camera model to precisely estimate the 3D pose in an unsupervised manner. It takes a 2D pose and camera parameters as inputs and produces the corresponding 3D pose estimation. These inputs are obtained from RegNet, which starts from a single image and provides estimates for the 2D pose and camera parameters. RegNet utilizes only 2D pose data as weak supervision. Internally, RegNet predicts a 3D pose, which is then projected to 2D using the estimated camera parameters. This process enables RegNet to establish the unambiguous 2D-3D relationship. Our experiments show that modeling the lifting as an unsupervised task with a camera in-the-loop results in better generalization to unseen data. We obtain state-of-the-art results for the 3D HPE on the Human3.6M and MPI-INF-3DHP datasets.
Materials
BibTeX
@article{garau2024epoch,
title={EPOCH: Jointly Estimating the 3D Pose of Cameras and Humans},
author={Garau, Nicola and Martinelli, Giulia and Bisagno, Niccol{\`o} and Tom{\`e}, Denis and Stoll, Carsten},
journal={arXiv preprint arXiv:2406.19726},
year={2024}
}