Lifting from the Deep: Convolutional 3D Pose Estimation from a Single Image



IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
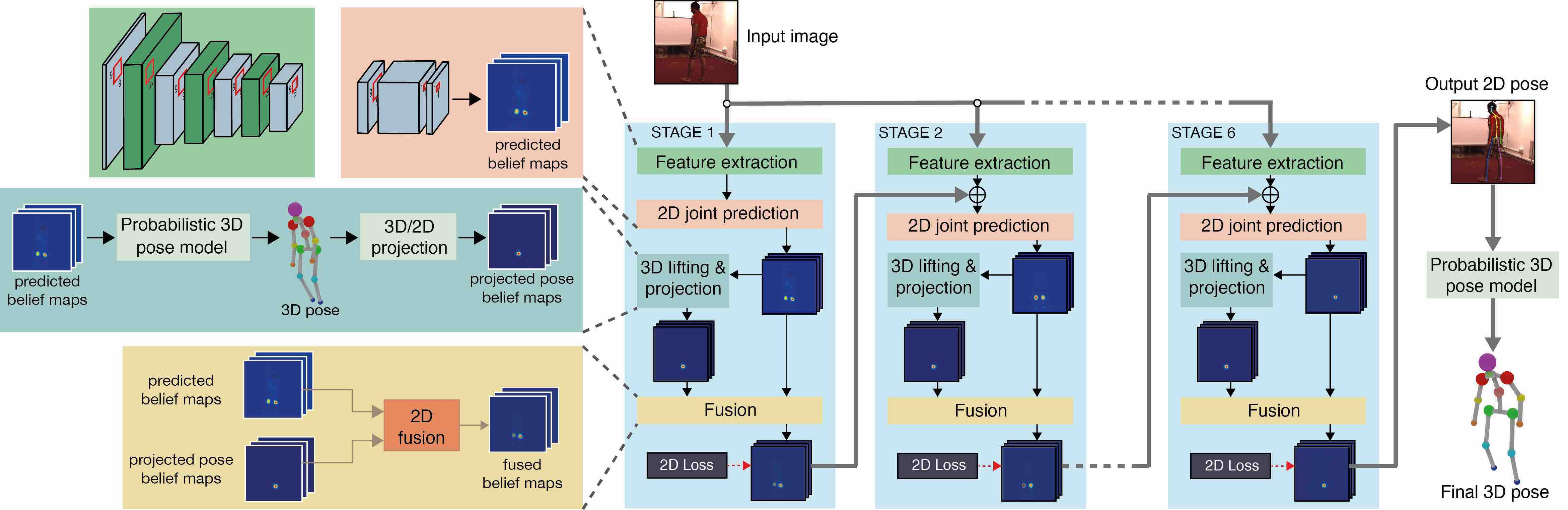
Abstract
We propose a unified formulation for the problem of 3D human pose estimation from a single raw RGB image that reasons jointly about 2D joint estimation and 3D pose reconstruction to improve both tasks. We take an integrated approach that fuses probabilistic knowledge of 3D human pose with a multi-stage CNN architecture and uses the knowledge of plausible 3D landmark locations to refine the search for better 2D locations. The entire process is trained end-to-end, is extremely efficient and obtains state-of-the-art results on Human3.6M outperforming previous approaches both on 2D and 3D errors.
Materials
BibTeX
@INPROCEEDINGS {8100086,
author = {D. Tome and C. Russell and L. Agapito},
booktitle = {2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
title = {Lifting from the Deep: Convolutional 3D Pose Estimation from a Single Image},
year = {2017},
volume = {},
issn = {1063-6919},
pages = {5689-5698},
doi = {10.1109/CVPR.2017.603},
url = {https://doi.ieeecomputersociety.org/10.1109/CVPR.2017.603},
publisher = {IEEE Computer Society},
address = {Los Alamitos, CA, USA},
month = {jul}
}